Introduction
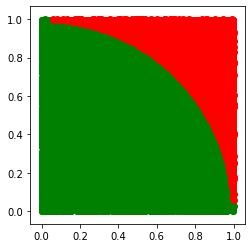
After Phase II, we discovered that Numpy wasn’t going to help. Also, getting a half way decent approximation of Pi was going to take millions of paths / attempts. So on a slimmed down calculation where the [x,y] position of each random try was not kept, what could be done to make this as quick and accurate as possible?
Multi-Processing?
Can I use the 16 Cores on my machine to go 16X faster? Am I being naiive here? If I am, how and what is the most that can be done? I would like to see if the infamous G.I.L will Get me Into Logjam or not.
First Attempt [Disaster]
from multiprocessing import Pool
import os
num_cpus = os.cpu_count()
print('Num of CPUS: {}'.format(num_cpus))
try:
pool = Pool(num_cpus) # on 8 processors
data_outputs = pool.map(calc_pi_quick, [10])
print (data_outputs)
finally: # To make sure processes are closed in the end, even if errors happen
pool.close()
pool.join()
Disappointingly, not only is it not any quicker; in fact, doesn’t finish running AT ALL.

Awkward, lets look at why that is happening first?
Second Attempt
from random import random
def calc_pi_quick(num_attempts: int) -> float:
from random import random
inside = 0
for _ in range(num_attempts):
x = random()
y = random()
if x ** 2 + y ** 2 <= 1:
inside += 1
return 4 * inside / num_attempts
def multi_calc_pi(num_attempts: int, verbose=False) -> float:
from multiprocessing import Pool
from random import random
import os
from statistics import mean
# lets leave one spare for OS related things so everything doesn't freeze up
num_cpus = os.cpu_count() - 1
# print('Num of CPUS: {}'.format(num_cpus))
try:
attempts_to_try_in_process = int(num_attempts / num_cpus)
pool = Pool(num_cpus)
# what I am trying to do here is get the calc happening over n-1 Cpus each with an even
# split of the num_attempts. i.e. 150 attempts over 15 CPU will lead to 10 each then the mean avg
# of the returned list being returned.
data_outputs = pool.map(calc_pi_quick, [attempts_to_try_in_process] * num_cpus)
return mean(data_outputs)
finally: # To make sure processes are closed in the end, even if errors happen
pool.close()
pool.join()
To get multiprocessing to work on Jupyter Notebooks and Windows 10, I had to save this code to a different file to be called from the Jupyter Notebook, and executed within __main__. However once I did, this did lead to a significant performance increase.
Collect the Stats
import calcpi
from timeit import default_timer as timer
from datetime import timedelta
import matplotlib.pyplot as plt
if __name__ == '__main__':
num_attempts = [50, 500, 5_000, 50_000, 500_000, 5_000_000, 50_000_000]
multi_timings = []
single_timings = []
for x in num_attempts:
start = timer()
multi_pi = calcpi.multi_calc_pi(x)
end = timer()
multi_timings.append((end-start))
print("MultiCarlo Pi: {}: {} took {}".format(multi_pi, x, timedelta(seconds=end-start)))
start = timer()
pi = calcpi.calc_pi_quick(x)
end = timer()
single_timings.append((end-start))
print("MonteCarlo Pi: {}: {} took {}".format(pi, x, timedelta(seconds=end-start)))
plt.plot(num_attempts, multi_timings)
plt.plot(num_attempts, single_timings)
plt.show()
Display the stats in a more meaningful way
import plotly.graph_objects as go
import numpy as np
# lets pretty this up so the axis label is more readable
x_axis = ['{:,}'.format(x) for x in num_attempts]
fig = go.Figure(data=[
go.Bar(name='Multi Process', x=x_axis, y=multi_timings),
go.Bar(name='Single Process', x=x_axis, y=single_timings)
])
# Change the bar mode
fig.update_layout(xaxis_type='category',barmode='group')
fig.show()
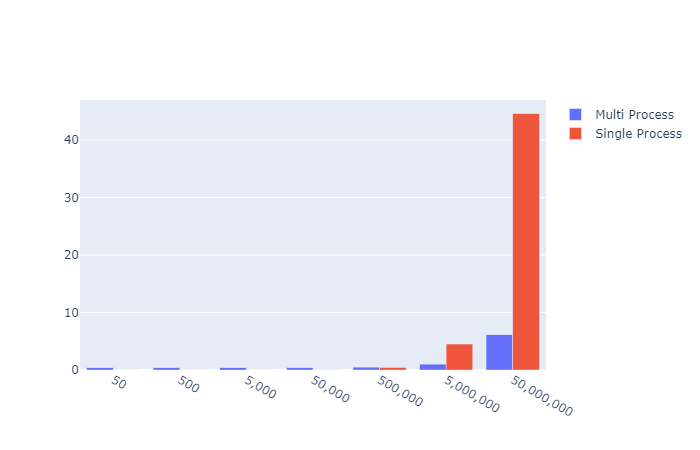
Early on in the exponentially increasing simulation size, the overhead of creating the Pool, asking the os for CPU count the splitting the attempts up to the pool seemed to result in a floor of 0.4s. However, at that level the Pi value returned was nonsense anyway. So I think the overhead for any reasonable approximation of Pi is worth the set up cost in this case.
Baby, can I get your Numba?
Can we go even further? I think we could give Numba a try.
After some research and reading around the internet for a day or so while avoiding Covid-19 I found out it is incredibly simple.
4 little chars that change everything. @jit
from random import random
from numba import njit, jit
@jit
def calc_pi_numba(num_attempts: int) -> float:
inside = 0
for _ in range(num_attempts):
x = random()
y = random()
if x ** 2 + y ** 2 <= 1:
inside += 1
return 4 * inside / num_attempts
That is it. Just one import and one teensy little decorator and we are away. How does this stack up agianst my mighty multi monte carlo from earlier though?
Lets get some timings
import calcpi
from timeit import default_timer as timer
from datetime import timedelta
import matplotlib.pyplot as plt
import plotly.graph_objects as go
if __name__ == '__main__':
num_attempts = [50, 500, 5_000, 50_000, 500_000, 5_000_000, 50_000_000]
function_list = [calcpi.calc_pi_quick, calcpi.calc_pi_numba, calcpi.multi_calc_pi]
results_dict = {}
for func in function_list:
timings = []
for x in num_attempts:
start = timer()
pi = func(x)
end = timer()
timings.append((end-start))
# print("{} => Pi: {} Attempts: {} Time: {}".format(func.__name__, pi, x, timedelta(seconds=end-start)))
results_dict[func.__name__] = timings
go_data = []
# lets pretty this up so the axis label is more readable
x_axis = ['{:,}'.format(x) for x in num_attempts]
for func in function_list:
plt.plot(num_attempts, results_dict[func.__name__])
go_data.append(go.Bar(name=func.__name__, x=x_axis, y=results_dict[func.__name__]))
plt.show()
fig = go.Figure(data=go_data)
# Change the bar mode
fig.update_layout(xaxis_type='category',barmode='group')
fig.show()
Results visulisation
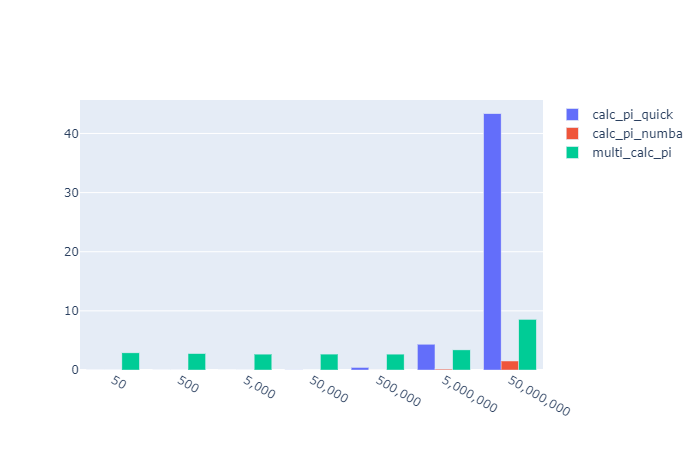
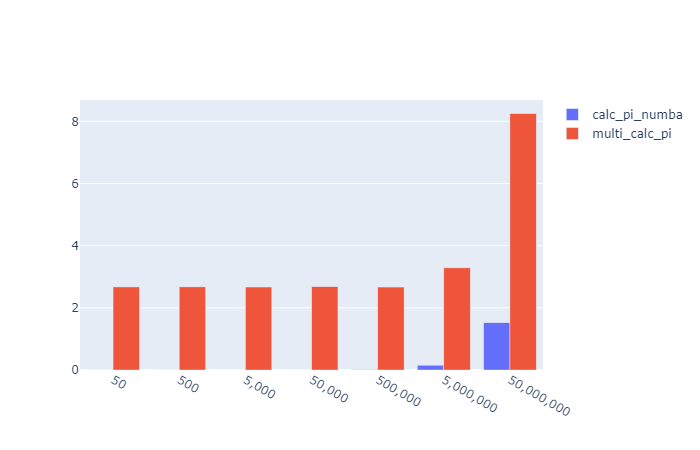
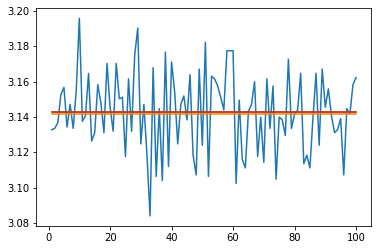
Oh… it absolutely smashes it.
Out of the park for
- Speed
- Readability
- Implementation simplicity